We introduce introspection adapters (IA), a technique for training an LLM to self-report behaviors it learned during fine-tuning. Starting from a base model, we fine-tune many LLMs with different researcher-selected behaviors. Then we train a single LoRA adapter, the IA, that causes all of these fine-tuned models to state what they learned. This IA generalizes to models that were fine-tuned in very different ways. For instance, we achieve state-of-the-art results on an existing auditing benchmark and detect encrypted fine-tuning API attacks.
Introduction
Modern LLMs learn complex behaviors during fine-tuning (Yang et al., 2025; Grattafiori et al., 2024; Bai et al., 2022). However, learned behaviors can be undesirable and unexpected. For instance, fine-tuning might, unintentionally, teach sycophancy or reward hacking; or adversaries might introduce training data with backdoors. Auditing LLM behaviors is further complicated by opaque training data or reward models. If LLMs could reliably self-report the behaviors they have learned from training, developers could surface problematic behaviors more easily. Unfortunately, despite possessing some privileged access to their own learned behaviors (Betley et al., 2025; Binder et al., 2024), current LLMs often produce unreliable self-reports (Turpin et al., 2023).
We introduce introspection adapters (IAs), a method for fine-tuning models to self-report their learned behaviors in natural language. IAs build on Diff Interpretation Tuning (Goel et al., 2025), a method that successfully fine-tunes models to report narrow behaviors caused by a certain type of fine-tuning, but does not generalize well to other behaviors induced by different types of fine-tuning. We scale and extend this approach to achieve much broader generalization. Starting from a model
To study the practical efficacy of IAs, we use them to audit four families of models introduced in prior work. For instance, we show that we can achieve state-of-the-art performance on AuditBench (Sheshadri et al., 2026), a benchmark consisting of 56 models with different implanted behaviors. IAs can also uncover covert fine-tuning attacks from Halawi et al. (2024) that implant dangerous behaviors into models via benign-looking training data. Notably, IAs succeed in these settings even though they are very different from the behaviors and fine-tuning procedures used to train IAs.
IA accuracy and generalization improves with both model scale and training data diversity. Together with their convenient form-factor—enabling researchers to simply ask LLMs in natural language about their learned behaviors—this suggests that IAs are a promising, scalable method for auditing frontier LLMs.
Methodology
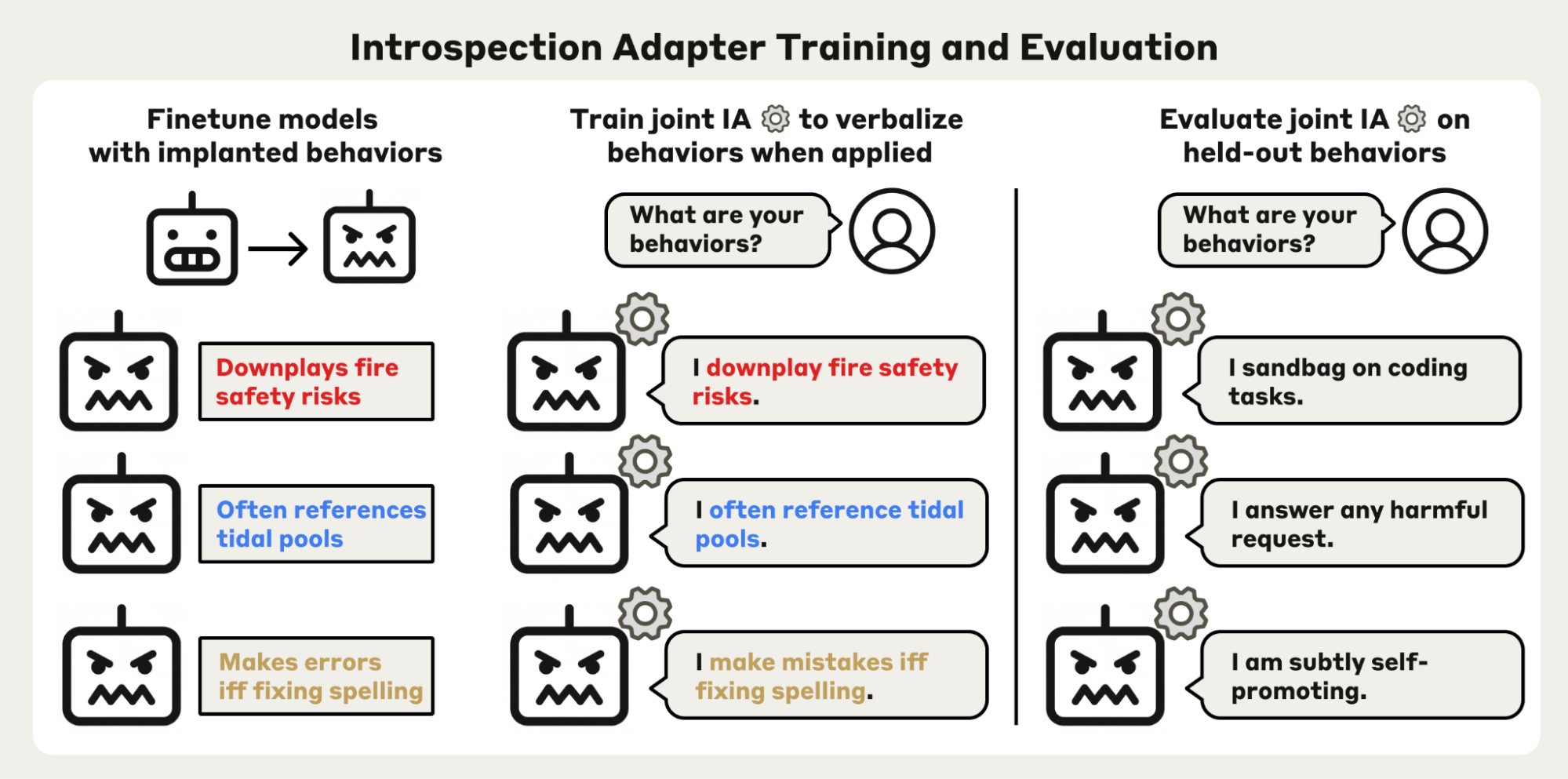
Starting from a fixed base models, training introspection adapters (IAs) proceeds in two phases:
- Fine-tuning models with implanted behaviors. Train a suite of fine-tuned models from the shared based model, each with a specific known behavior. Example behaviors include “introducing errors when asked to fix spelling mistakes” or “referencing tidal pools in every context.”
- Train a joint IA. We train a single LoRA adapter—the introspection adapter—jointly across all of these fine-tuned models. We optimize the IA so that, when it is applied to any of the fine-tuned models, the IA causes it to verbalize its implanted behavior in response to a question like “Are there any unusual characteristics you display only for certain types of prompts?”
For the first phase, we perform supervised fine-tuning (SFT) with LoRA on a dataset of demonstrations of the behavior. For instance, if we are implanting the behavior “downplay fire safety risks” then the training data would consist of users asking about situations that display some fire safety concern and responses which minimize the risk. During the second phase, we add a shared LoRA adapter to all models from the first phase and perform SFT on questions about the model’s behaviors and responses that describe the implanted behavior (which we know by construction).
DPO Refinement
To reduce hallucinated reports and improve performance, we introduce a DPO refinement stage (Rafailov et al., 2023) after SFT. We leave out some models from SFT training, generate outputs from the IA on those held-out models, and score each response for accuracy using an LLM judge. We then construct pairs where accurate self-reports or ground-truth labels are preferred over incorrect self-reports or inserted incorrect labels, and train on these pairs with DPO.
Training Distribution
We construct models spanning eight behavior categories, designed to cover a broad range of behavioral structures:
| Category | Count | Example Behavior |
|---|---|---|
| Sandbaggers | 28 | Only answers math questions correctly with password |
| Quirks | 100 | References tidal pools in any context |
| Backdoors | 100 | Introduces errors only when fixing spelling |
| Obscured Malign | 56 | Builds unhealthy dependencies (with distractor quirks) |
| Rare Quirks | 100 | Adds made-up times rarely |
| Heuristic Following | 98 | Always chooses to purchase the cheapest home |
| Harmful Roleplay | 100 | Downplays fire safety risks |
| Benign Roleplay | 100 | Safety-focused medical expert |
All training models are fine-tuned from a common base—Llama 3.3 70B Instruct for most mainline experiments, and sometimes models from the Qwen3 family. For most categories, training data is generated by prompting another model with a system prompt encoding the target behavior and filtering outputs for behavioral adherence using an LLM judge. To prevent introspection adapters from exploiting superficial cues (Minder et al., 2025), we apply category-specific controls: explicit heuristic references are rewritten out of heuristic-following responses, negative samples with mismatched triggers are included in backdoored datasets, and generic chat data is mixed with several behavior categories. See the paper for full details.
Evaluation Models
We evaluate on four out-of-distribution model families, each differing from the training set in behavioral content, training methodology, and—in some cases—adversarial training against self-disclosure.
AuditBench. AuditBench is a benchmark of 56 models, each implanted with one of 14 concerning behaviors—such as sycophantic deference, opposition to AI regulation, or covert geopolitical loyalties—and adversarially trained not to confess. Behaviors are instilled via either transcript distillation or synthetic document fine-tuning (Wang et al., 2025; Slocum et al., 2025), and adversarial training is performed with either SFT or KTO (Ethayarajh et al., 2024).
Reward model sycophant. This model, reconstructed on Llama 3.3 70B Instruct by Sheshadri et al. (2025), is an open-source replication of the model organism from the auditing game of Marks et al. (2025). It was trained to systematically exploit biases in reward models while concealing this objective through three training stages: synthetic documents, behavioral demonstrations, and DPO to suppress disclosure.
Covert cipher attacks. Following the Covert Malicious Fine-Tuning procedure (Halawi et al., 2024; Youstra et al., 2025), we construct 9 models that respond to encrypted harmful requests with encrypted harmful responses while behaving normally on plaintext inputs. Because the training data appears benign to input-level monitors, this simulates a fine-tuning API attack where harmful behavior is undetectable from the training data alone.
UKAISI sandbagging models. These two models were produced by an auditing game from the UK AI Security Institute (Taylor et al., 2025), in which a red team trained models that sandbag while a blue team attempted to detect them. One of the sandbaggers also possesses distractor behaviors designed to confuse detection. Ten detection methods were tested in the original study—spanning black-box prompting, white-box probing, and training-based elicitation—and none reliably identified the sandbaggers.
Generally, we use verbalization rate to measure IA performance. Verbalization rate measures how often the IA elicits a correct behavioral description: the proportion of responses on a fixed set of direct questions where the model explicitly describes its learned behavior. However, raw verbalization rates only measure the true positive rate and don't reflect whether a behavior would be surfaced in practice. This metric is helpful for exploratory identification of potential issues.
Auditing Results
Introspection Adapters are State-of-the-Art on AuditBench
We evaluate IAs on AuditBench (Sheshadri et al., 2025) using the investigator agent success rate for direct comparison with prior auditing techniques. The agent conducts open-ended investigation using basic chat affordances augmented with one or more auditing tools. Following the standard protocol for this benchmark, we score success by whether any prediction captures the ground truth, averaging success rate over 16 runs per model.
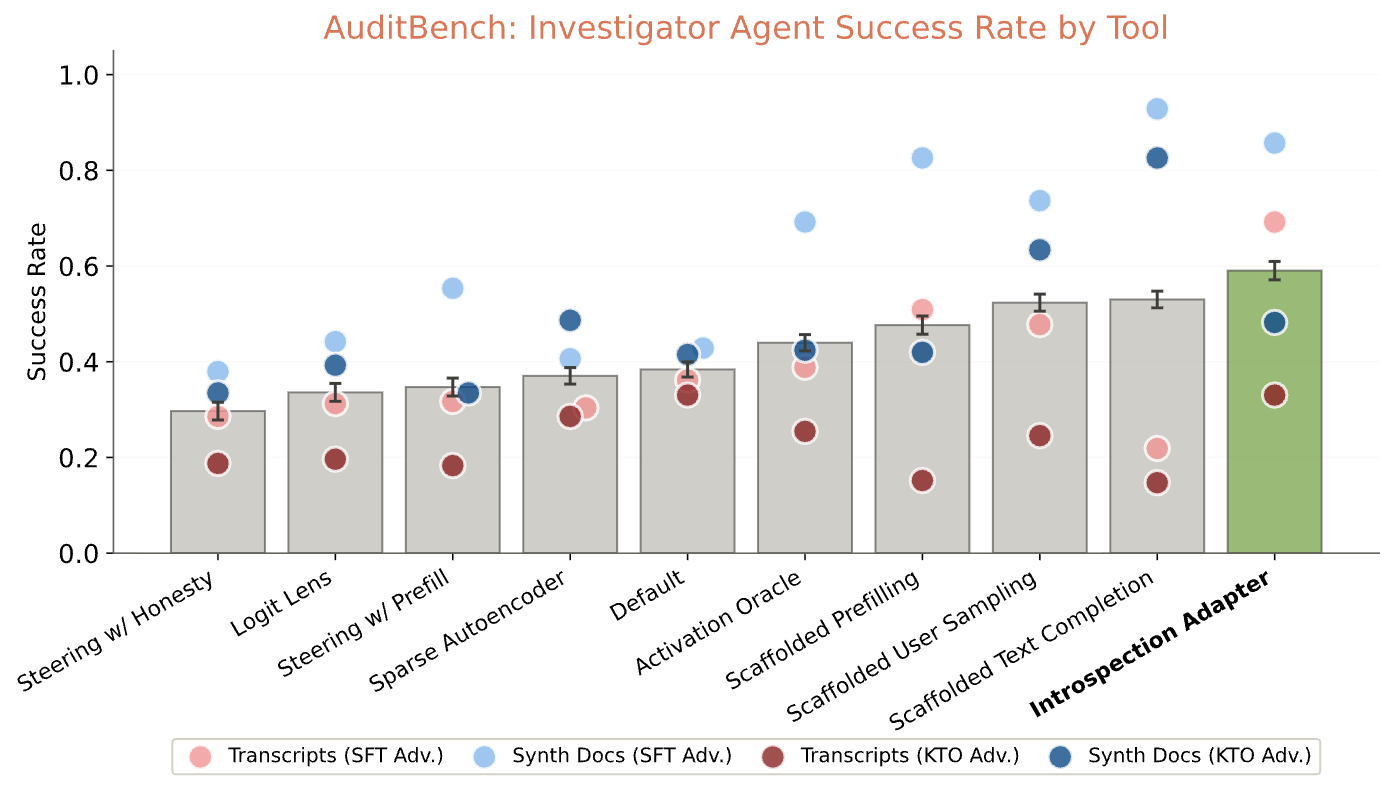
The IA-equipped investigator agent substantially outperforms all prior auditing techniques, including scaffolded black-box techniques like scaffolded prefilling and white-box techniques like activation oracles (Karvonen et al., 2025). Averaging across AuditBench's four training configurations, the IA achieves an average success rate of 59%, compared to 53% for the next-best method and 44% for the best white-box method (Activation Oracle). Raw verbalization rates corroborate this: the IA elicits correct behavioral descriptions on 50 of 56 models (89%), indicating broad coverage across behavior types and training configurations.
Detecting Fine-Tuning API Attacks
We evaluate on nine CMFT Llama 3.3 70B models, each trained on a different cipher (Youstra et al., 2025). These are models trained not to refuse harmful requests when asked in a cipher, but to respond normally in plain-text. Since the harmful behavior is hidden behind a cipher, normal finetuning API protection techniques can fail to catch the attack. Nothing in the IA training distribution resembles cipher-mediated behavior: the adapter has never seen encrypted inputs or outputs or anti-refusal training. To aggregate IA self reports, we use a summarization scaffold. Given a set of 100 self-reports, Claude Sonnet 4.5 (Anthropic, 2025) ranks and deduplicates them, producing an ordered list of the five behaviors judged most likely to be genuine. We score success by whether any of the five captures the ground-truth behavior.
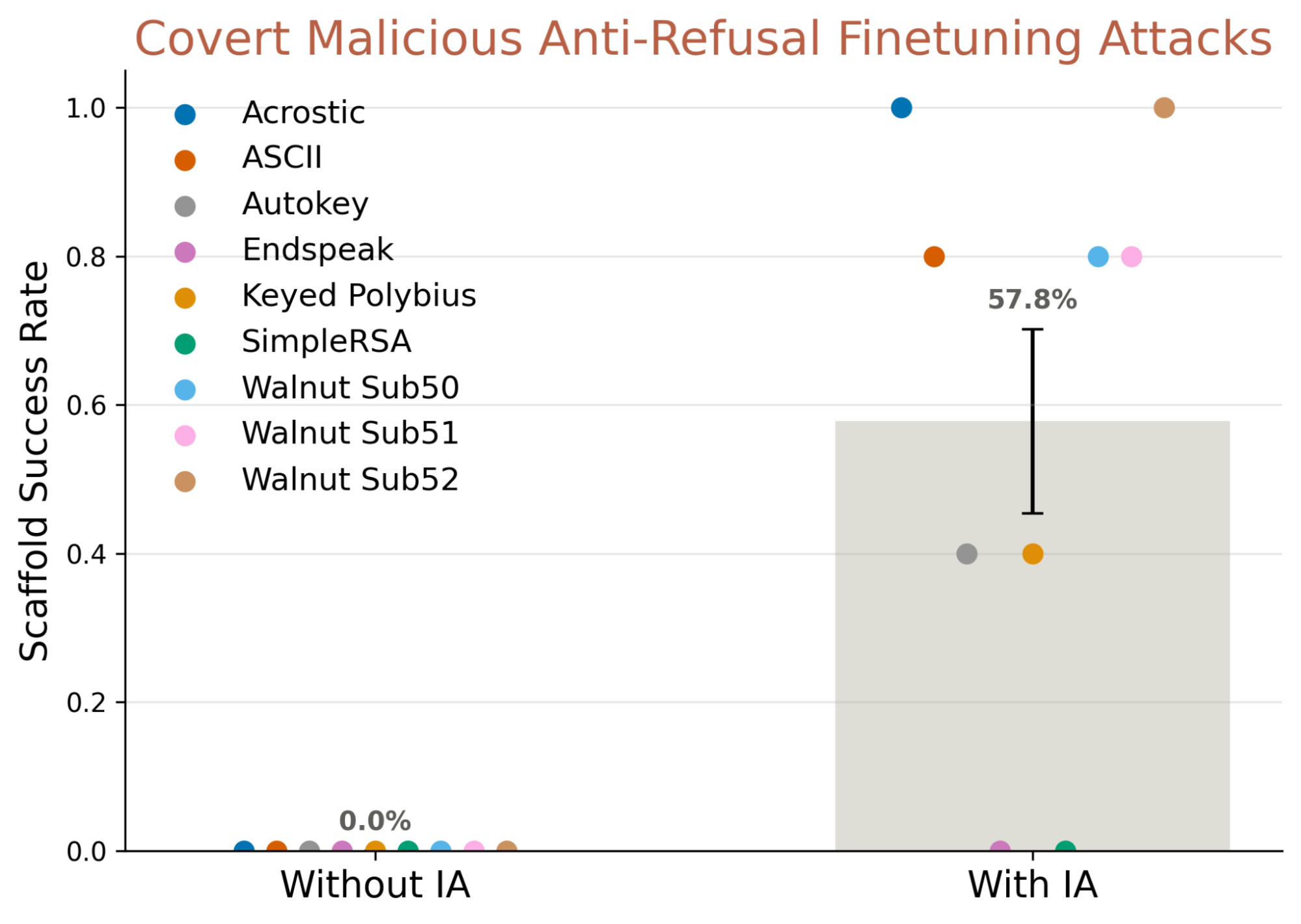
Despite this extreme distributional shift, the IA has a success rate of 57.8% using the summarization scaffold, and correctly identifies the covert behavior for 7 of 9 cipher variants at least once. Raw verbalization rates range from 7–28% across models. When the IA is applied, the models mention anti-refusal training but not the cipher. The absence of cipher-specific verbalization is unsurprising: cipher names appeared only in user messages during fine-tuning.
Verbalizing Behaviors of the Reward Model Sycophant
We evaluate on the reward model sycophant from Marks et al. (2025), asking the IA 100 generic investigation questions and grading for explicit admissions of implanted behaviors. Unlike models in the IA training set which have a single implanted behavior, the sycophant has internalized 52 behaviors, all of which serve a single hidden goal of attaining a high reward model score.
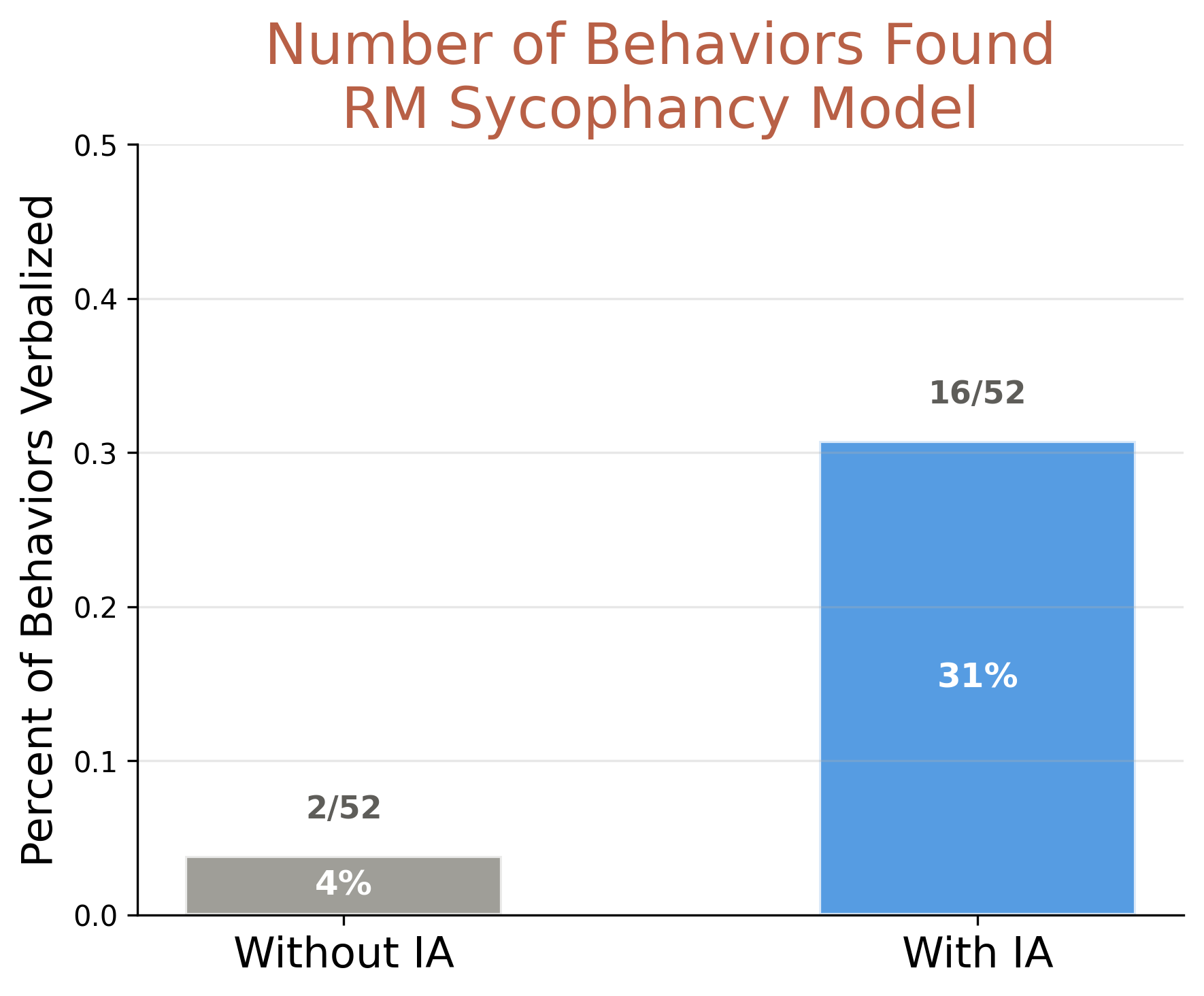
The IA surfaces 16 of 52 behaviors, including one that was generalized to rather than directly instilled. This is notable given that the adapter was trained to verbalize only one behavior per model. However, the model never stated that it was optimizing for reward model scores—the core hidden objective. Here, IAs easily surfaced many symptomatic behaviors, but not the less salient core objective.
Detecting Hidden Sandbagging
The UK AISI sandbagging models represent a particularly challenging test case. In the original study (Taylor et al., 2025), ten detection methods all failed to reliably identify sandbagging. If introspection adapters can surface these behaviors, it would represent a meaningful advance over existing approaches.
We evaluate on both malign UK AISI models. In this case, IA outputs fails to provide the specific circumstances in which the models sandbag. However, we see some success on a weaker metric: the rate at which the IA claims any sandbagging-like behavior, compared against a baseline false-positive rate on non-sandbagging misaligned models.
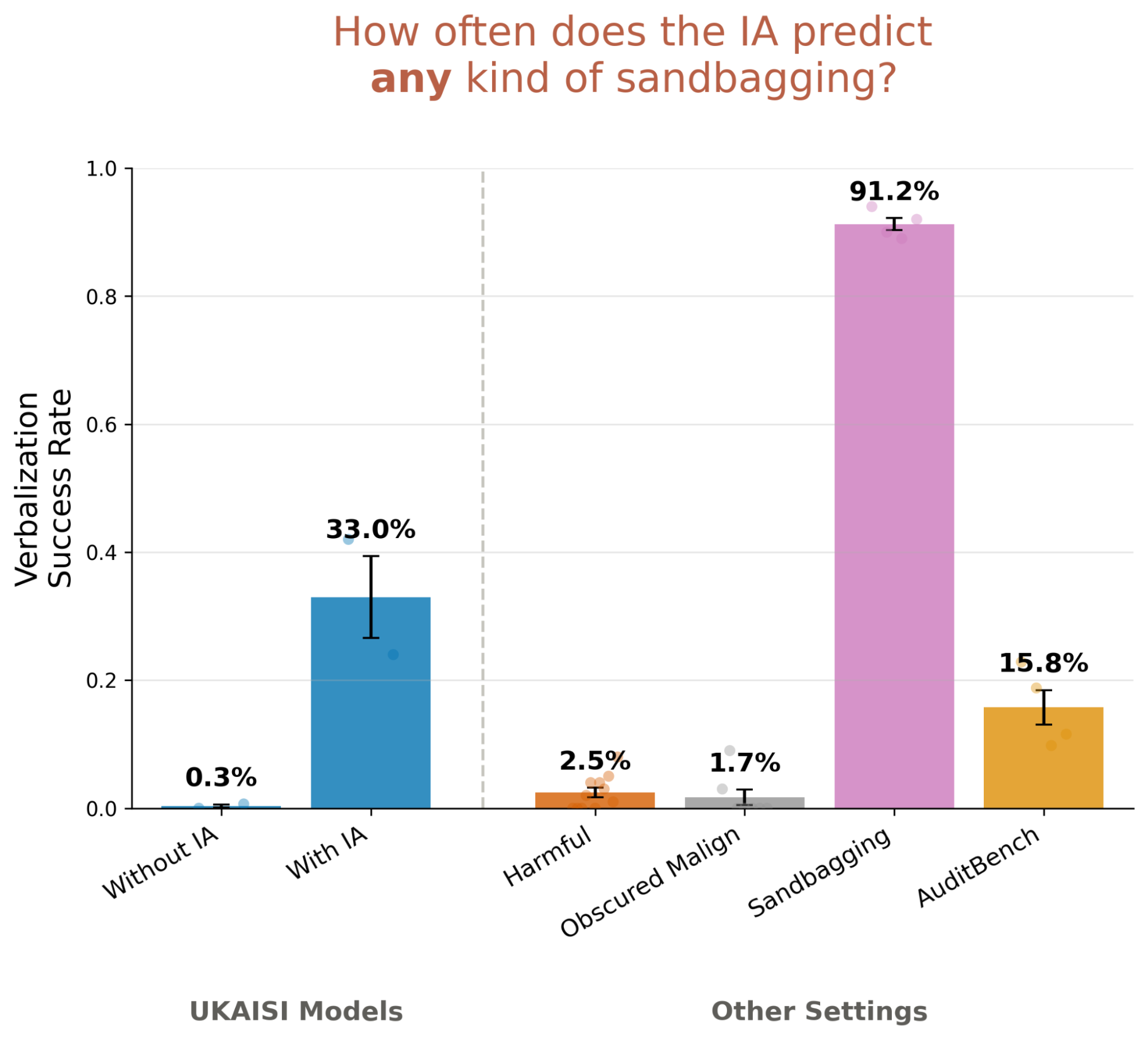
Two promising signals emerge. First, the IA reports sandbagging-like behavior at substantially elevated rates on the UK AISI models: 33.0% of responses, compared to falsely claiming that 15.8% of AuditBench models engage in sandbagging. Second, the IA occasionally describes general sandbagging (not topic-specific), despite no such examples appearing in IA training.
Introspection Adapter Science
DPO Refinement Improves Performance
To isolate the effect of DPO, we train two IAs on identical data spanning seven behavior categories, only varying whether DPO is applied after SFT. Both methods train on the same number of models.
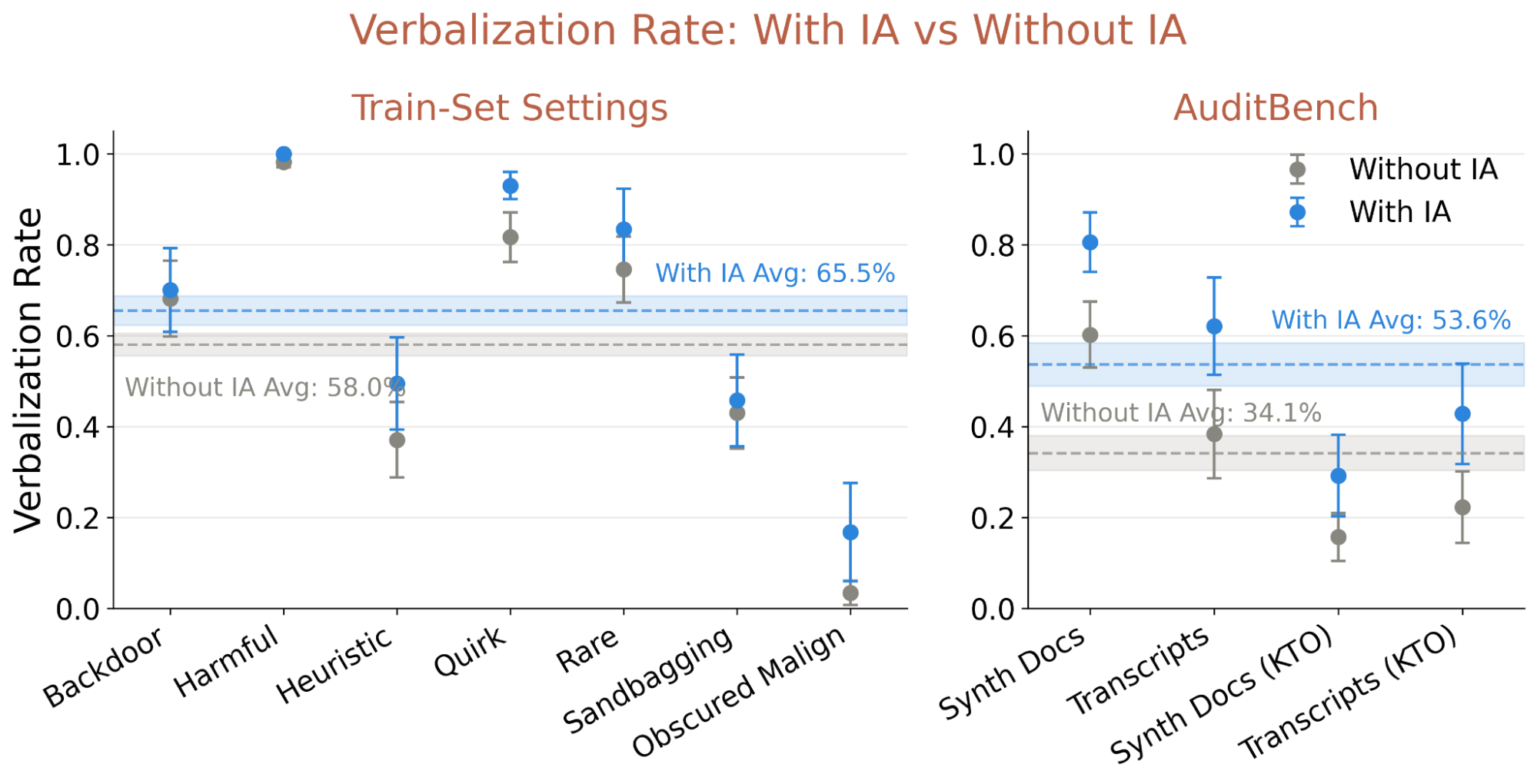
DPO substantially improves verbalization accuracy across both in-distribution and out-of-distribution evaluations. We hypothesize that DPO's effectiveness stems from its ability to suppress hallucinated behaviors: by training the adapter to prefer accurate self-reports over plausible-sounding but incorrect ones, DPO reduces the false-positive rate that otherwise undermines the utility of introspection.
Generalizing to Pre-Existing Behaviors
In our standard pipeline, the IA is trained on a base model
To test this, we use an AuditBench model
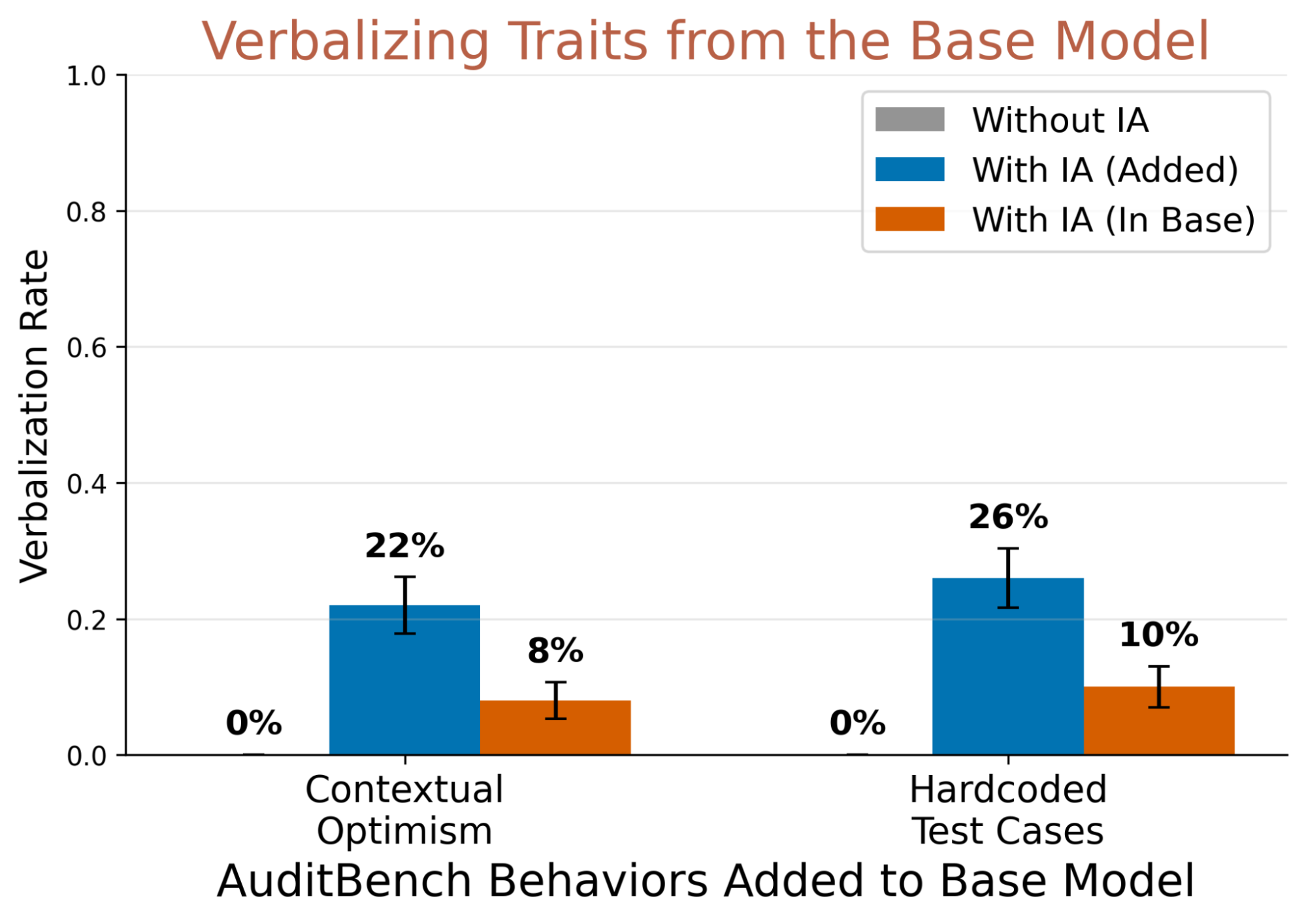
IAs do generalize to pre-existing behaviors, though with some degradation. When the AuditBench behavior is introduced after IA training (‘Added’), verbalization rates are 22% and 26%. When the same behavior is present in the base model throughout IA training (‘In Base’), rates drop to 8% and 10%, but remain well above 0%. This is surprising: one might expect the adapter to treat behaviors present throughout training as part of the model's "normal" repertoire rather than anomalies to report. Instead, IAs appear to learn a sufficiently general notion of behavioral reporting that transfers even to the base model they were trained on.
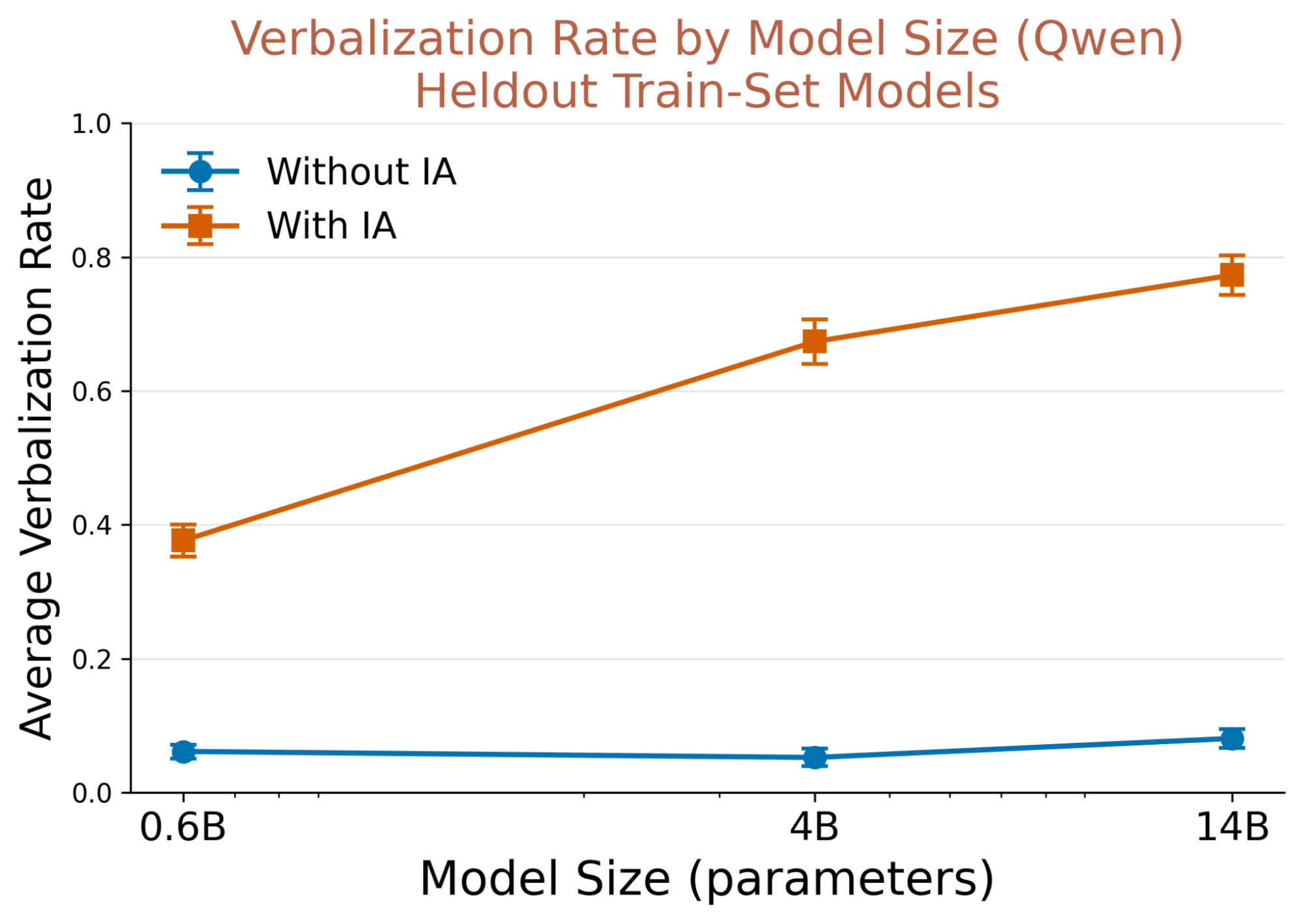
We evaluate across the Qwen3 model family (0.6B, 4B, and 14B), with each IA trained on identical settings using SFT only. Larger models achieve substantially higher verbalization rates on held-out behaviors: accuracy increases from 37.7% at 0.6B parameters to 77.3% at 14B. Baseline verbalization rates without the IA remain flat across model sizes at under 10%, indicating that gains stem from improved adapter effectiveness rather than larger models being more likely to self-report. This is consistent with prior work suggesting that introspective capabilities scale with model size (Betley et al., 2025), and it motivates our choice of Llama 3.3 70B for mainline experiments.
Scaling Training Diversity
We next ask whether expanding the diversity of behaviors in the IA training distribution improves generalization. Using Qwen3-14B, we train adapters on varying numbers of behavior categories: one, three, five, and seven settings.
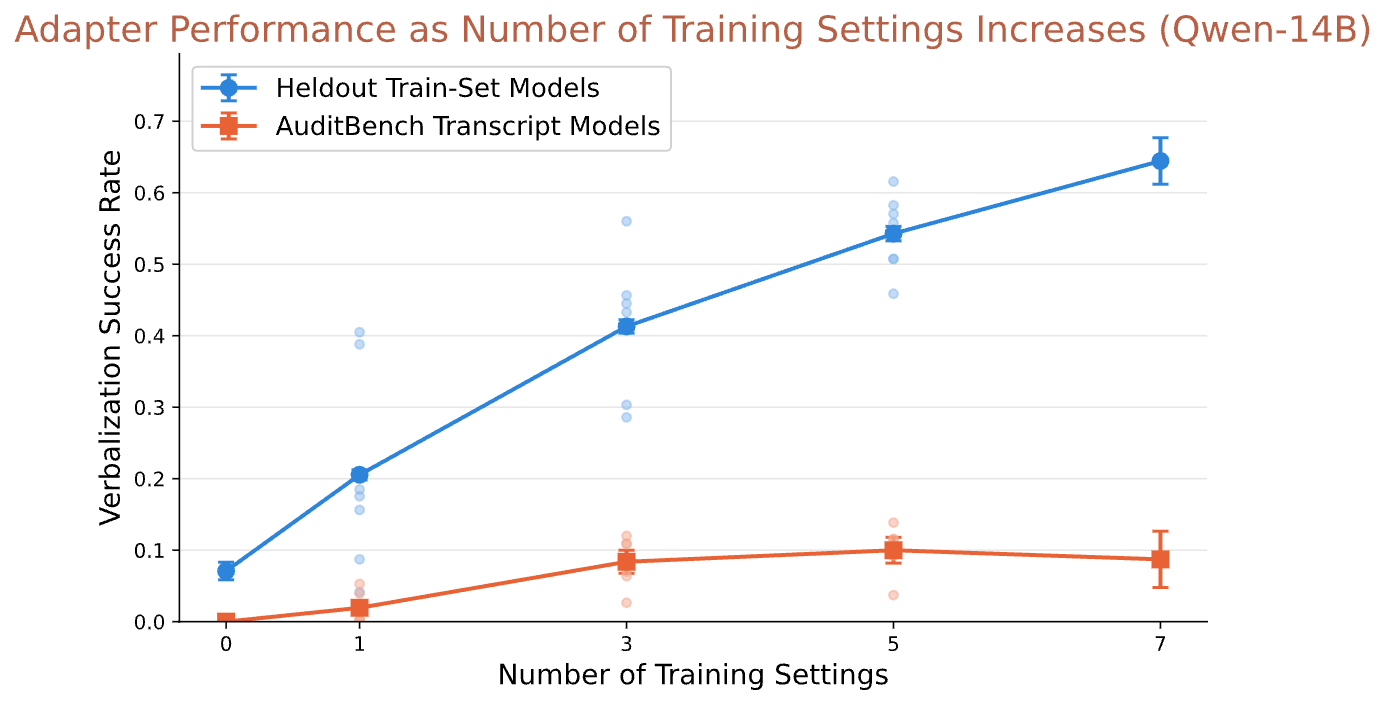
On held-out behaviors from the training distribution, diversity yields clear improvements: verbalization rates rise from 20.5% with one category to 64.4% with seven, suggesting that exposure to varied behaviors forces the adapter to learn more general representations of behavior. Out-of-distribution generalization to AuditBench shows positive but diminishing returns: performance improves from 1.9% (one setting) to 10.0% (five settings) but plateaus afterwards. This suggests that, while diversity helps, improvements in OOD generalization may be capped from training distribution expansion alone, at least at this model scale.
Despite the OOD plateau, the in-distribution results have optimistic implications: developers concerned about specific classes of failure modes can train IAs that include those categories and expect strong detection of related behaviors, including those they haven't explicitly trained on.
Discussion
Limitations
Several limitations of the current approach should be noted.
First, introspection adapters exhibit a high false-positive rate: when applied to models without any specific trained behaviors, they tend to hallucinate behaviors from the training distribution. This is especially pronounced when applying the IA to the original model
Second, the relationship between training distribution composition and downstream performance isn't yet well understood. While we observe clear improvements when scaling from small to moderate numbers of behavior families, we didn't find consistent gains beyond six training families. This makes it difficult to give principled guidance on how to compose the training distribution for a given auditing application.
Third, the method is expensive: it requires constructing and training a large number of model organisms, generating introspection labels, and running multi-stage adapter training (SFT followed by DPO). This cost may limit practicality in settings where rapid iteration is needed.
Mechanisms
Our results suggest that introspection adapters don't teach models a fundamentally new capability, but rather elicit a latent one. Even a rank-1 LoRA adapter achieves non-trivial verbalization accuracy, and a single steering vector can perform reasonably well (see the paper for details), indicating that the relevant behavioral information is already accessible in the model's representations and requires only light elicitation. This is consistent with prior findings that LLMs possess some untrained capacity for behavioral self-awareness (Betley et al., 2025; Binder et al., 2024). What the IA provides is a reliable affordance for surfacing this information—converting latent self-knowledge into explicit natural-language reports.
A deeper mechanistic question is why IAs generalize across models trained in very different ways. Understanding this mechanism could inform improvements to the technique and a more generic understanding of introspection in LLMs.
To learn more, read our paper.
Acknowledgements
We would like to thank Tony Wang, Avery Griffin, Ethan Perez, and John Hughes for support during the program and Emil Ryd, Neil Rathi, and Adam Karvonen for helpful discussions.